Why Good Enough Document AI Is Not Good Enough
Most mortgage lenders have already made the move to AI-powered document processing. The question in 2026 is not whether to automate – it is whether the solution you have is actually working. For a lot of lenders, the honest answer is no. Documents are getting processed, but the output is unreliable enough that teams are spending significant time downstream doing manual rechecks, correcting bad data, and cleaning up exceptions that should never have made it through intake in the first place.
This paper is for lenders who want to stay ahead of one of the industry’s most persistent bottlenecks: document processing solutions that fall short, quietly driving up costs and pushing problems further down the loan lifecycle.
Where the real costs show up, and it is not just headcount
Most lenders have already invested in some form of automation or AI to address document processing. But those solutions are falling short in ways that are easy to underestimate, because the failures tend to be quiet and distributed rather than loud and obvious.
- Incorrect filing and naming conventions that force downstream teams to hunt for what they need
- Versioning issues that leave processors working off the wrong document without realizing it
- Data extraction errors that pass through intake undetected and surface later as exceptions
- Heavy manual pre-cleanup and corrective action that erodes whatever efficiency the automation was supposed to deliver
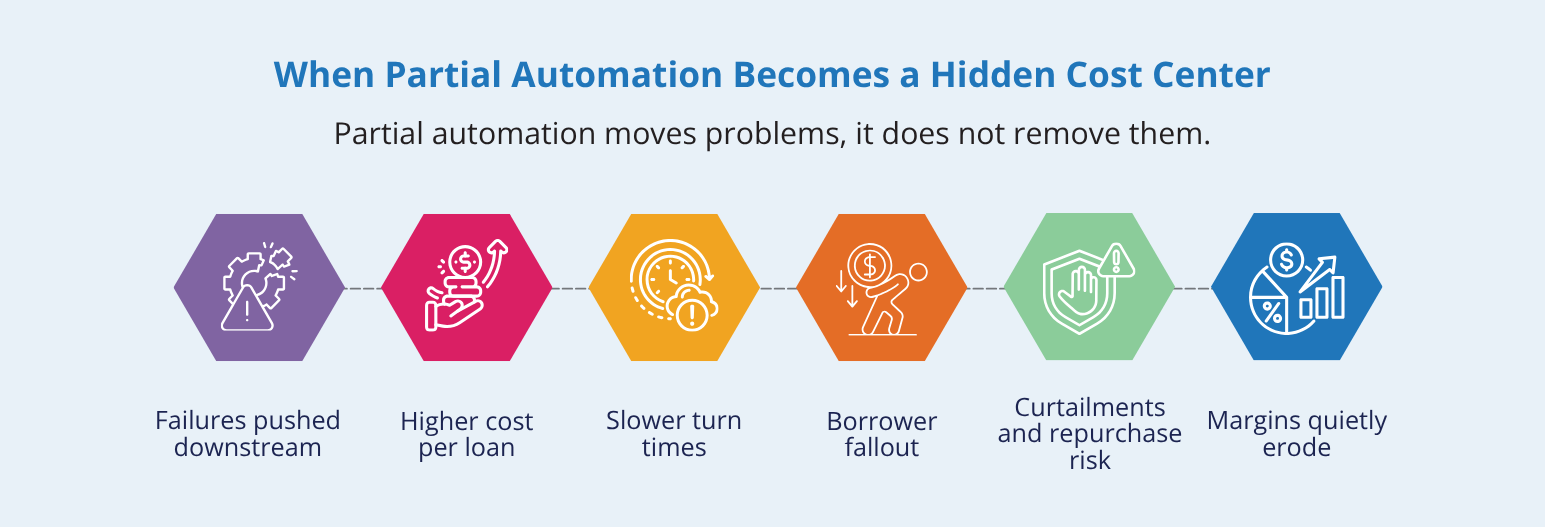
The document technology is in place. The problem is that partial automation does not deliver partial results, it often just moves the failure point further down the line, where fixing it costs more. Cost per loan climbs because manual document handling is labor-intensive at every touch; intake, indexing, exception review, and re-work when something gets missed.
Curtailments increase because investor deadlines do not care about your document backlog. When turn times stretch, interest shortfalls follow.
Turn times lengthen in ways that are hard to explain to borrowers. A loan that stalls in processing because a document was misclassified or rekeyed incorrectly does not feel like a technology problem to the borrower. It just feels like a slow lender.
Borrower fallout rises as a direct result. Longer cycle times mean more opportunities for a borrower to get a competing offer, lose patience, or simply walk away.
Repurchase risk grows when document exceptions that should have been caught at intake surface later in the lifecycle … sometimes long after the loan has been sold.
The staffing problem is real. But these are the costs that compound quietly, loan by loan, until they start showing up in margins.
What most document AI solutions actually deliver
The pitch from most document processing vendors sounds compelling: automated extraction, reduced manual work, faster turn times. The reality that lenders experience after implementation tends to look different.
Most solutions on the market today, including OCR-based tools and the document processing modules bundled into leading LOS platforms, were built to solve a digitization problem, not a data quality problem. They can get a PDF into a system. What they cannot reliably do is get the right data out of it in a way that people downstream can actually trust and act on.
The gap shows up in three ways that matter
Extraction without context
When a field is pulled incorrectly, reviewers have no way to see where in the document the value came from. There is no visual link between the extracted data and its source. That forces processors to open the PDF separately, hunt for the relevant section, and manually verify what the system should have shown them in the first place. The automation created a step, not eliminated one.
Poor data organization that creates its own errors
Some platforms surface hundreds of extracted fields in effectively random order, spread across multiple pages, with related data elements separated from each other. A fee name on one page, the corresponding dollar amount three pages later. Reviewers are left mentally reconstructing relationships that the software should have preserved. At scale, that is not a minor inconvenience – it is a systematic source of error and a guaranteed bottleneck.
Cryptic outputs that require workarounds to use
When the interface is too difficult to work with directly, operations teams build their own translation layer: job aids, field ID reference sheets, and manual lookup processes, just to bridge the gap between what the system extracted and what a human can verify. That overhead compounds with every loan, and it means the organization is now dependent on institutional knowledge to operate a tool that was supposed to reduce that dependency.
Not built for mortgage
Underneath many of these shortcomings is a more fundamental issue: most document AI solutions are not purpose-built for mortgage. They are general-purpose tools applied to a highly specific problem, built without a deep understanding of how the mortgage process actually works. That matters because document accuracy in early origination is not just an intake issue. Underwriting, closing, servicing, and secondary market teams all depend on data that was captured correctly at the front of the process. A solution that was not designed with that downstream reliance in mind will optimize for extraction volume rather than extraction accuracy, and the costs of that tradeoff show up everywhere else in the lifecycle.
That gap is sharpest on the documents that carry the most risk: income statements, VOEs, VOIs, and closing disclosures. These are exactly the document types where generic tools consistently break down.
What AI-driven document processing actually looks like in practice
There is a tendency to oversell AI in mortgage as something that replaces human judgment. The better platforms do not work that way. What they actually deliver is closer to a very fast, very consistent document specialist that feeds your people cleaner inputs so they can make better decisions faster. The key word is purpose-built. A platform designed specifically for mortgage understands the documents, the workflows, the investor requirements, and the downstream dependencies that a general-purpose tool simply was not designed to handle.
A solid machine learning platform for mortgage documents directly addresses the gaps that plague most existing solutions.
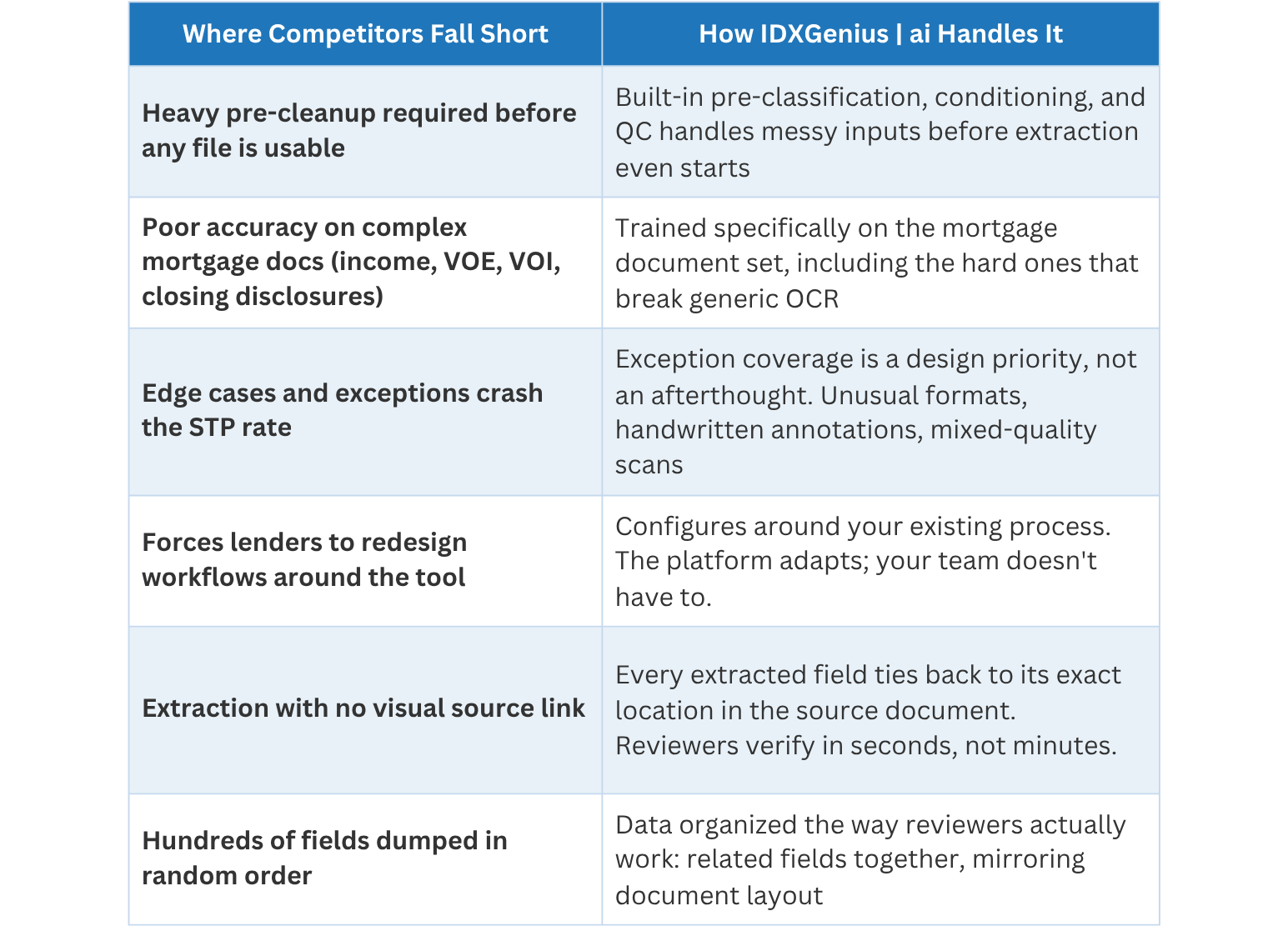
Robust pre-classification and conditioning before extraction starts.
The step that most platforms skip entirely. Before any data gets extracted, files need to be assessed, sorted, and conditioned. Low-quality scans, mixed-format packages, handwritten annotations – these are not edge cases in production.
Extraction with context, not just extraction.
When a field is pulled from a document, reviewers should be able to see exactly where in the document it came from without opening a separate PDF and hunting manually. A purpose-built platform ties extracted data directly to its source location, so validation is fast.
Data organized the way reviewers actually work.
Related fields should appear together, in the same order they appear in the document. Fee names next to fee amounts. Income figures grouped with their supporting detail. When extracted data mirrors the document layout, reviewers can move through a file quickly and accurately.
Anomaly detection that catches what humans miss at scale.
Values get compared across documents automatically. If something does not line up, the system flags it before it becomes an exception finding or a repurchase request. This is not a manual recheck. It is a systematic layer of validation that runs on every loan, every time.
What to look for when evaluating platforms
Generic document tools and mortgage-specific platforms are very different. Integration is where most implementations succeed or fail. A platform that sits outside your core stack will not deliver its promised value. Bidirectional integration with your LOS, servicing system, and repositories is what makes zero-touch processing work. The metrics that matter are document coverage, field-level accuracy, straight-through processing, and reduced human touches per file. Speed helps, but accuracy drives downstream value. Also ask about pre-classification and conditioning. If a demo only shows clean, well-formatted files, ask how it handles the messy documents your team actually receives every day.
Where IDXGenius | ai fits into this picture
IDXGenius | ai was built specifically for this problem. It combines proprietary machine learning, generative AI, and AWS infrastructure to handle document-heavy processes across the full mortgage lifecycle, from origination through servicing and into capital markets. Because it was designed as a mortgage automation engine and not a generic OCR tool, it understands the documents, the workflows, and the downstream dependencies that matter in this industry.
The platform handles document classification, data extraction, indexing, and validation without requiring manual intervention at each step. It supports loan setup, underwriting, post-closing QC, servicing onboarding, MSR transfers, and due diligence out of the box. Pre-classification and conditioning are built in, not bolted on. Complex document types – income, VOE, VOI, closing disclosures – are handled with accuracy rates that generic tools do not achieve. And it configures around your existing workflows rather than forcing your team to rebuild their process around a new tool.
For lenders who have already invested in document AI and are still fighting the same problems, IDXGenius | ai is built to close the gap.